Background
Recently, I came across this blog post written by Vicki Boykis in which she documented her process of building a Twitter bot that tweets Soviet artworks in scheduled intervals. Inspired by the idea (and motivated by boredom), I decided to build a Twitter bot myself that tells questionably coherent stories through a series of tweets. I loved this idea because first of all, I love literature, especially the classics. In the meantime, I had been wanting to learn how to deploy a model on AWS and call it using the famous Lambda function. Therefore, having nothing better to do, I set out to do exactly that.
In the end, I built something that I was rather proud of. In particular, I trained a language model using Jane Austen’s novels available on Project Gutenberg1 and created a Twitter bot that, given an initial prompt of “it is a truth universally acknowledged,” the famous opening line of Pride and Prejudice, went on to generate subsequent sentences, one tweet at a time, every 6 hours. Of course, the resulting story was not totally coherent given my limited training data and the simple model architecture, but my focus of this project was not exactly the quality of the model but rather its productionization. Therefore, seeing it live on Twitter, I was quite happy with the result. In fact, some of the generated tweets were rather entertaining, like the opening line below:
it is a truth universally acknowledged , that it is not worth while to be married , and that the worst of it was possible for her to marry him .
— What would Gutenberg say (@gutenberg_says) November 13, 2019
Very Jane Austen, as one would say.
One recurring mistake that I noticed was that the model often mixed up the gender pronouns and produced sentences like below:
he must be a very good sort of woman , though i am sure i should be a very good - natured man . "
— What would Gutenberg say (@gutenberg_says) November 13, 2019
Perhaps more data or a longer training time would help.2 Yet, for a side project, I would call it a day and not spend any more money on it. Perhaps, in the future, I would train more models based on some of my other favorite writers. If you are interested in following a seemingly readable yet practically nonsensical story told in the tone of a classic writer, you can follow my bot below :)
In the rest of the post, I will describe my process of building this bot in detail, with a focus on the AWS deployment.
Product requirements
I started by listing everything that I wanted my bot to do, namely:
- Given a single prompt, the program needs to automatically generate all subsequent sentences. Given that a single tweet can not exceed 280 characters, in order to ensure the “coherence” between tweets, at the end of each tweet, the program needs to save the last generated word as well as the last model states (which, in LSTM, are just the final cell and hidden states), reload them in the next call, and feed them into the model as the new prompt and initial states.
- After a tweet-long content is generated, the bot needs to post it on Twitter.
- The program needs to be triggered in a fixed interval without human intervention.
To meet the first requirement, I needed to make sure my model outputs the final states along with each prediction and save them, as well as the final word prediction, in S3 and reuse them in the next iteration. To tweet programmatically in Python, I relied on the Twython package. Finally, to trigger the program periodically, I created a rule to do so on Amazon CloudWatch. More details are given in the sections below.
Architecture design
With the above requirements in mind, I came up with the following design:
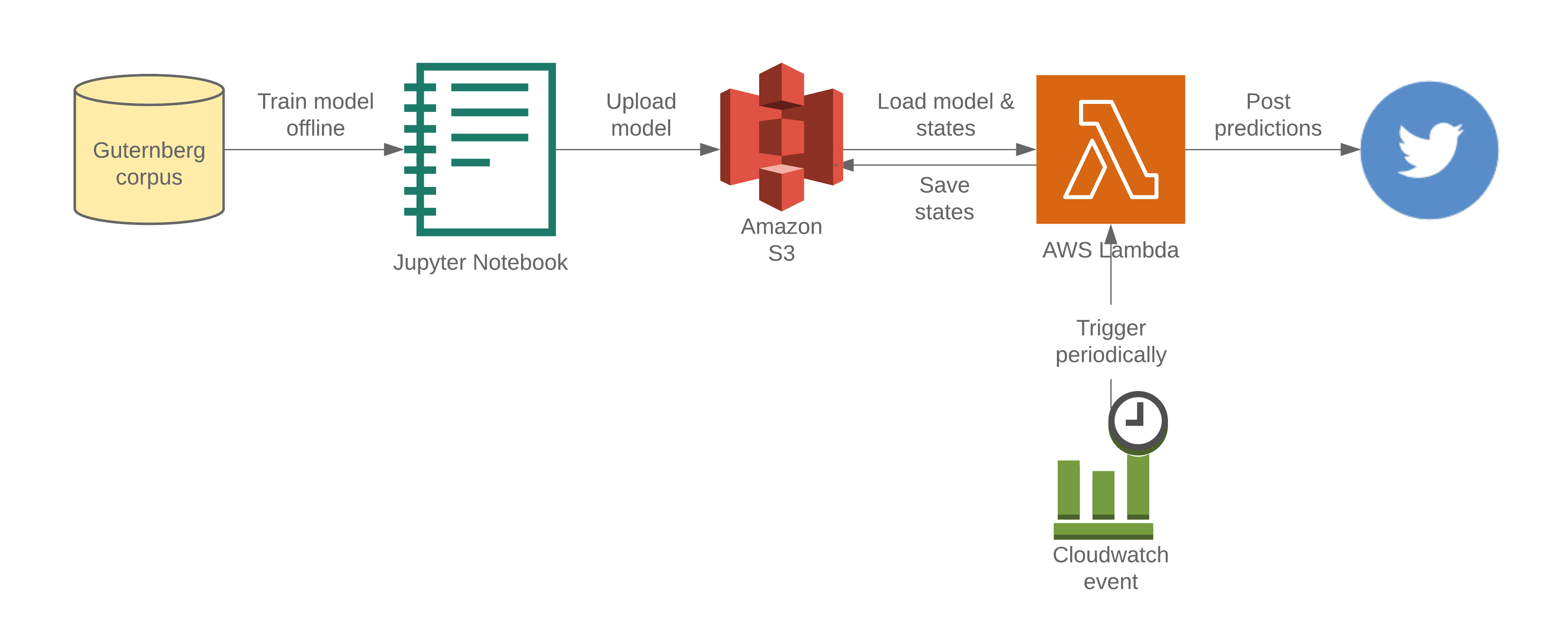
In the sections below, I will quickly describe my model, which was really nothing special, and dedicate the remainder of the post to the deployment process.
Language model
Since the model itself was not the focus of this project, I built a very simple language model that consisted of only two layers of LSTMs. The only thing worth mentioning is that, because I needed to output the final states in addition to the word predictions, instead of using the trained model directly (which only output the latter), I needed to reconstruct the model during the inference time to include the states in the output.3 For more details, you can refer to my Jupyter Notebook here.4
Deployment
Because it was the first time I deployed a model on AWS, I spent a tremendous amount of time reading documentation and blog posts just to figure out the simplest things. Hence, to make my future life easier, I’m going to document meticulously what I did below. If you happen to be going through the same process as I was, I hope you will find it helpful too.
Create the AWS credentials
If it is the first time you use AWS, you need to start by creating a user for yourself and give it enough permissions by following these steps.
Configure the AWS CLI
Next, follow these steps to set up the AWS CLI using the access keys created at the end of the first step above. In my case, the CLI allowed me to easily upload my model and other files to S3.
Create an S3 bucket
An S3 bucket is where I saved my offline model and the supporting files. To create one, I followed this tutorial.
Upload the files to S3
To upload the offline model and other files to S3, I ran the following command using the CLI (placeholders are wrapped in brackets):
aws s3 cp {local_file_path} s3://{bucket_name}/{s3_file_path}
Install the Serverless Framework
From its website, the Serverless Framework “helps you build serverless apps with radically less overhead and cost. It provides a powerful, unified experience to develop, deploy, test, secure and monitor your serverless applications.” I will not try to elaborate on that because I will probably do it wrong. Instead, I will simply explain why I decided to use it from a practical standpoint.
To take a step back, to deploy a model on AWS, one does not necessarily need to use the Serverless Framework. The only reason that I resorted to it is because of its excellent management of the dependency libraries, particularly in the following two aspects:
- The ability to use Docker to install all the dependency libraries. Once again, one does not need Docker to package the dependencies. Instead, one can simply zip them oneself and point the Serverless Framework to find it. However, in my experience, my packaged libraries could not be properly imported on AWS Lambda, which might have something to do with the different environments. According to the Serverless Framework, “Docker packaging is essential if you need to build native packages that are part of your dependencies like Psycopg2, NumPy, Pandas, etc.” Hence, for a common data science project, there is no way to bypass Docker.
- The ability to zip and reduce the size of the libraries. This is, in my opinion, the biggest benefit of using the Serverless Framework, in particular, the Serverless Python Requirements plugin. AWS Lambda has some very strict size limits that, without the plugin, I found it literally impossible to include all my dependencies. Specifically,
- The unzipped deployment package size needs to be under 250 MB. Note the emphasis on “unzipped.” Tensorflow by itself is more than 400 MB, so there is absolutely no way to include it in the upload. To overcome the limit, the Serverless Framework uploads the zipped packages but does not tell Lambda that they are packages so the latter cannot unzip them itself. (If it does, the size limit would be exceeded.)5 Then, once on Lambda, it unzips them itself during the runtime and imports them as usual. It’s so hacky that I love it.
- However, we are not done yet. In the runtime, AWS allocates a
/tmpdirectory to the program where one can save the model files downloaded from S3. However, this/tmpdirectory is also shared with the unzipped packages and it has a size limit of 512 MB. Once again, even if we bypassed the upload limit of 250 MB by uploading a zip file of dependencies, ultimately we would need to unzip them to/tmpto import them properly. Hence, we may still run over the new 512 MB limit, which is exactly what happened to me. Even though my model object was not big (60 MB), together with some large dependencies (e.g., Tensorflow, Numpy, Scipy), I went over the 512 MB easily. To overcome the problem, the Serverless Framework implements a “slim” option that “strip[s] the.sofiles, remove[s]__pycache__and dist-info directories as well as.pycand.pyofiles.” After this operation, my total usage of the/tmpdirectory is finally reduced to 480 MB, barely escaping the limit.
If you think all these solutions are hacky and we are pushing the limits of AWS Lambda, I completely agree with you. Honestly, I don’t think the platform is made to deploy deep learning models. The new Amazon SageMaker looks more suitable for the task but is also significantly more expensive :/
Regardless, to install the Serverless Framework, one needs to first install Node.js, which, in MacOS, can be done using Homebrew:
brew install node
Next, install the framework and the Serverless Python Requirements plugin mentioned above:
npm install -g serverless
sls plugin install -n serverless-python-requirements
Write serverless.yml
serverless.yml is the config file for the service. There are many examples of it online. I kept mine very minimal and only included the following essential sections. (The complete file can be accessed here for reference.)
First, define the service provider including the bucket that was created earlier:
provider:
name: aws
runtime: python3.6
region: {region}
deploymentBucket:
name: {bucket_name}
Then, reference the handler function, which is a function that “AWS Lambda can invoke when the service executes your code.” In my case, I only needed it to do three things: 1) load the trained model, 2) generate predictions, and 3) post the result on Twitter (more on this in the following section). In serverless.yml, I referenced my handler function as follows (placeholders are wrapped in brackets):
functions:
{function_name}:
handler: {the_name_of_the_file_where_the_function_is_defined}.{function_name}
timeout: 300
I added a timeout argument because when calling the function, the default timeout is 6 seconds. However, in my case, it takes almost that long to just load all the dependencies for the first time, so I increased the timeout to 5 minutes.6
Next, we need to specify the plugins that we use. In my case, I only used one.
plugins:
- serverless-python-requirements
Finally, add the operations that we want this plugin to do, namely, installing the dependencies in a Docker, zipping the packages to upload, and stripping the unnecessary components to reduce the size.
custom:
pythonRequirements:
dockerizePip: true
zip: true
slim: true
Write the handler function
Instead of pasting over the code snippets, I am going to describe what the function does below. The complete code can be referenced here.
- Using the Boto 3 Python client library, I first downloaded the previously-uploaded model from S3 per its documentation. Note, I needed to first download it to the abovementioned
/tmpdirectory and then load it to the memory usingKeras’sload_modelfunction.7 Using the same functions, I also downloaded and loaded the model’s meta data (e.g., vocabulary, index mapping) and the previous model states, which would become the initial states in the current iteration, as well as the last word prediction, which would become the new prompt. - Generate a sequence of words using the new initial states and prompt until the end of sentence token is encountered or the maximum character length (280) is met. To inject some randomness and variety into the generation, I incorporated an idea from this codebase which introduced an extra
temperatureargument that controls for how much one would want to consider the less optimal predictions by adjusting the predicted probabilities accordingly. In particular, as one gradually reduces thetemperaturefrom 1.0 to 0.0, the differences among the predicted probabilities are exaggerated, which makes the smaller probabilities now even smaller than the bigger ones, thereby making it even rarer for Numpy’smultinomialsampler to choose it. On the contrary, the greater thetemperature, the more “creative” the result becomes. - To post anything on Twitter programmatically, one first needs to create a Twitter developer account here and create an app to get the consumer key and secret as well as the access token and secret. To avoid passing them in plain text, I saved and encrypted them in the environment variables provided by the Lambda function. To actually initiate a Twython instance and tweet something, one can follow its documentation here.
Test locally
To test the Lambda function locally before deploying it to AWS, run the following command:
serverless invoke local -f {handler_function_name}
The command may throw an error saying the function does not have permission to access S3. To fix that, one needs to assign such a privilege to the function by attaching the corresponding policies. In my case, I went to the IAM management console, found my Lambda function under the “Roles” section, and attached the “AmazonS3FullAccess” policy to it.
Deploy
To deploy the handler function along with all the dependencies, simply run:8
serverless deploy
Note, there are a few different options one can append to the command above. I didn’t experiment much with them myself since my use case was rather straightforward but you may find them helpful.
Test the online deployment
To actually invoke the function that is deployed on AWS Lambda, simply remove the keyword local in the previous command:
serverless invoke -f {handler_function_name}
The complete logs of each invocation can be found in the “Logs” section of CloudWatch, accessible from the console.
And that’s really all there is to it! In my experience, I spent the vast majority of the time (in fact, two days) trying out various tricks to downsize my dependencies as much as possible to meet AWS’s strict size limits, which was really not fun! Due to my poor internet upload speed, each deployment took a very long time to finish, which made the feedback loop very long. I certainly hope AWS will either increase the size limit or pre-install some of the popular data science libraries on Lambda in advance.
Set CloudWatch event
Finally, to schedule the program, I created a simple rule that invokes it every 6 hours by following these steps. And with that, ladies and gentlemen, it was all done.
Next steps
As mentioned in the beginning, the quality of the language model as of now leaves a lot to be desired. Hence, when I have more time in the future, I will start by training it longer. In fact, after 60 epochs, the validation loss was still declining steadily so there is still potential for improvement. Moreover, I’m also interested in adding other writers’ works in my dataset to blend their styles together. It would certainly be a dream to read something written by my favorite writers all at the same time!
References
Lastly, I want to end this post by citing the following three blog posts that I found the most helpful. Thank you for taking the time to document your learnings! It has made the lives of us new learners much easier.
- Vicki Boykis, Building a Twitter art bot with Python, AWS, and socialist realism art
- kagemusha_ , Scraping on a Schedule with AWS Lambda and CloudWatch
- Oussama Errabia, Deploy Machine Learning Models On AWS Lambda
- Why Jane Austen? Because I found her books having just the right amount of drama and satire. [return]
- I trained the model for 60 epochs, which, on a single Quadro P4000 GPU provisioned by Paperspace, took about 16 hours. [return]
- During training, I could not include states in the output because I didn’t have ground truth labels for them. [return]
- The model was written in
Keras. [return] - After all, this is just my guess. [return]
- Latency is not a concern for this product. [return]
- Note,
Keras’sload_modelfunction relies on theh5pypackage, whose latest version, 2.10.0, somehow doesn’t work well with the Serverless Framework’sslimoption. Fortunately, downgrading it to the previous 2.9.0 version solved the problem. [return] - If you need to overwrite the previously-installed packages, you may need to first remove the locally cached version by running
rm -rf /Users/{user_name}/Library/Caches/serverless-python-requirements/. [return]